Evaluation Metrics for supervised Learning

In real world machine learning we will encounter a lot of different evaluation metrics, sometimes we need to create our own custom evaluation metrics based on the problem, But in this notebook we will see some of the most commonly used evaluation metrics.
In classification the most common metrics used are:
- Accuracy
- Precision
- Recall
- F1-Score
- Area under the curve or (area under the ROC(receiver operating characteristic) curve) AUC
- Log loss
Above metrics can also apply for multi class classification. we will see for binary and multi class level implementation of these metrics in this notebook
Before going through this article please refer below kaggle notebook so that you can run the code and edit as per your assumption.

Let’s first build a basic classification model to apply all our evaluation metrics
Building the Model
Loading the breast cancer dateset from sklearn
# the data is in the type of dict in this cell will check the key
# and value assoicated with it
for key in dataset.keys():
print(key)##### output #######data
target
frame
target_names
DESCR
feature_names
filenameprint("Total no of features: ",len(dataset['feature_names']) ,'\n\n')
for index, feature in enumerate(dataset['feature_names'], start=1):
print(index, feature)Total no of features: 30
1 mean radius
2 mean texture
3 mean perimeter
4 mean area
5 mean smoothness
6 mean compactness
7 mean concavity
8 mean concave points
9 mean symmetry
10 mean fractal dimension
11 radius error
12 texture error
13 perimeter error
14 area error
15 smoothness error
16 compactness error
17 concavity error
18 concave points error
19 symmetry error
20 fractal dimension error
21 worst radius
22 worst texture
23 worst perimeter
24 worst area
25 worst smoothness
26 worst compactness
27 worst concavity
28 worst concave points
29 worst symmetry
30 worst fractal dimension# Loading the dataset in pandas dataframe for analysis the dataset
data = pd.DataFrame(dataset['data'], columns= dataset['feature_names'])
data['target'] = pd.Series(dataset.target)
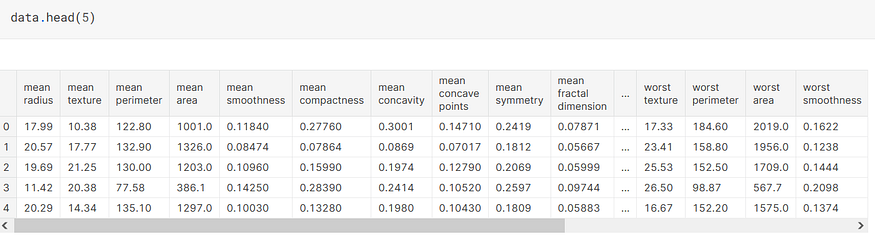
# to check the shape of the entire dataset
data.shape(569, 31)# Check if dataset is blanced or not that is to check if both the class label are partially equal or not
data.target.value_counts().sort_values().plot(kind = 'bar')
print(data.target.value_counts())1 357
0 212
Name: target, dtype: int64
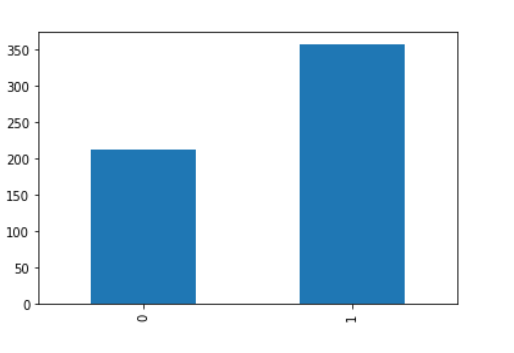
Observations: From the above analysis we can conclude that the its a binary classification problem and having 30 features all of float type and we have total 569 instance with no null values. based on the 30 values we need to classify if person is having breast cancer or not
X = data.drop(['target'],axis=1)
y = data[['target']]
X.shape, y.shape### output #########((569, 30), (569, 1))
X = data.drop(['target'],axis=1)
y = data[['target']]
X.shape, y.shape#### output ######3333((569, 30), (569, 1))# spliting the data into train and test
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X,y, test_size=0.33, random_state=42)x_train.shape, x_test.shape((381, 30), (188, 30))# Training the model
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=3)
model.fit(x_train,y_train.values.ravel()) # .values will give the values in an array. (shape: (n,1) and .ravel will convert that array shape to (n, )
y_pred = model.predict(x_test)(y_pred)array([0, 0, 0, 1, 1, 0, 0, 0, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 0, 0, 1,
0, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 0, 1, 0, 1, 1, 0, 1, 1,
1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1,
0, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0,
1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 1, 0, 1, 1,
0, 1, 1, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 0, 0, 0,
0, 1, 1, 0, 1, 1, 0, 0, 1, 0, 1, 1, 0, 1, 0, 0, 0, 1, 0, 1, 1, 1,
1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1,
0, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1])y_test = (y_test.values.ravel())
Now we have our y_test and y_predicted so we will learn here which metrics should be used based on data and target. Lets start with simple accuracy metrics.
Accuracy:
Accuracy is simple and very basic metrics which commonly used in machine learning. It defines how accurate our model is.
Example if we have 100 total test points in that 50 points as postive and 50 as negitive our model classifies 90 data points(Xq or instances) as positive then our model accuracy is 90%. if only 73 points as correct points then its 73% accuracy.
It can be also defined as number of correctly classified points to that of total number of points.
Accuracy = No. of correctly classified points / total no. of points
Custom accuracy funcion
custom_accuracy = accuracy(y_test,y_pred)
print(accuracy(y_test,y_pred))0.9414893617021277from sklearn.metrics import accuracy_score
print(accuracy_score(y_test, y_pred))
sklearn_accuracy = accuracy_score(y_test, y_pred)0.9414893617021277# Check both custom and sklean accuracy is same or not
custom_accuracy == sklearn_accuracy # True means we have not made any mistakes in the implementation.True
Note: we cannot use accuracy as a metrics when we have imbalance data(label skewed distribution).

As mentioned above if we use accuracy as the metrics for imbalance data suppose we have 90 positive points and 10 negitive points support our model outputs positive for any query(Xq) or instance point as positive its a very dumb model that what every its input is just return them as positive then also we get the accuracy as 90 as it will predict all the points as positive. so we need to better metrics.
Precision:
Before learning about precision we need to understand few terms:
- True positive (TP): Given an instance, if our model predict as positive and the actual value is also positive then it is considered as true positive.
- True negative (TN): Given an instance, if our model predict as negative and the actual value is also negative then it is considered as true negative.
In short: If your model correctly predict the positive class then its true positive and if your model correctly predict the negative class as negative then its a true negative
- False positive (FP): Given an instance, if our model predict as positive and the actual value is negative then it is considered as false positive.
- Flase negative (FN): Given an instance, if our model predict as negative and the actual value is positive then its a false negative.
In short: If you model incorrectly predicts the positive class, it is a false positive, if your model incorrectly predicts negative class then its a false negative.
Let’s implement all the above four terms:
Note: If you want to describe the accuracy using above terms, we can write it as Accuracy score = (TP+TN)/(TP+TN+FP+FN)
Lets implement accuray score using TP,TN,FP and FN
We can quickly check the correctness of this function by comparing it to our previosuly implemented and scikit-learn version accuracy
# custom accuracy, verion 2 accuracy using tf/tn/fp/fn, sklean accuracy
accuracy(y_test, y_pred), accuracy_v2(y_test, y_pred), accuracy_score(y_test, y_pred)(0.9414893617021277, 0.9414893617021277, 0.9414893617021277)
Now, lets start learning about percision
Precision = TP/(TP + FP)
Precision is the ratio of True Positives (TPs) to all the positives predicted by the model (TP + FP).
Let’s say we make a new model on the new skewed dataset and our model correctly identified 80 non-cancer out of 90 and 8 as cancer out of 10. Thus, we identified 88 correct instances out of 100 successfully. The accuracy is therefore, 0.88 or 88%
But, out of these 100 samples, 10 non-cancer data instance are misclassified as having cancer and 2 cancer patient are misclassified as not having cancer.
Thus, we have:
- TP : 8
- TN : 80
- FP : 10
- FN : 2
so, our precision is 8/(8+10) = 0.444. This means our model is correctly 44.4% times when its trying to identify positive samples
Now, as we have implemented TP, TN, FP and FN, we can easily implement precision in python.
from sklearn.metrics import precision_score
precision(y_test, y_pred), precision_score(y_test, y_pred)(0.9583333333333334, 0.9583333333333334)
So, we can conclude that our custom precision and sklearn precision are same
The higher number of FPs our model predicts, the lower the value of Recall. Mathematically speaking, a larger denominator leads to a smaller fraction.
Is it a good measure of performance?
The answer again highly depends on the task at hand.
Let us take a bit less depressing example, where we want to identify Patient having breast cancer or not.
If we misidentify an non-cancer patient as cancer, we increase the False Positive (FP) error. If we misidentify a cancer patient as non-cancer, we increase the False Negative (FN) number.
In this case, the cost of FP is higher than the cost of FN because every FP case will make us miss cancer patient, while we can deal with non-cancer patient by performing more test on the patient but we cannot miss the cancer patient.
Hence, in this case, we want to get every cancer patient. In other words, we need to minimize the number of non-cancer patient to be cancer
When we need to be more confident about the True Positives (TP and )minimize the False Positives (FP = 0) and , we aim for a perfect Precision, i.e., Precision = 1 (or 100%).
Precision tells us how precise are we with identifying a specific label. Such as, how many out of those we labeled as ill are actually ill? (Here, ill is Positive confirmation and healthy is Negative confirmation).
Recall or Sensitivity:
Recall (or Sensitivity) is the ratio of True Positives (TP) to all the correct predictions in your dataset (TP + FN). False Negatives are included here because they are actually the correct predictions too.
Recall = TP/(TP + FN)
from sklearn.metrics import recall_score
recall(y_test, y_pred), recall_score(y_test,y_pred)(0.9504132231404959, 0.9504132231404959)
So, from the above we can say that our custom recall and sklearn recall values are same
The higher number of FNs our model predicts, the lower the value of Recall.
Is it a good measure of performance?
The answer again highly depends on the task at hand.
Let us take an unfortunate but realistic example related with the COVID-19 pandemic:
If we misidentify affected by the coronavirus patients as healthy, we increase the False Negative (FN) error. If we misidentify healthy people as coronavirus-affected patients, we increase the False Positive (FP) number.
In this case, the cost of FN is higher than the cost of FP because every FN case will continue spreading the virus around, while the FP will not.
Hence, in this case, we need to identify every COVID-19 infection!
When we need to eliminate the False Negatives (FN = 0), we aim for a perfect Recall, i.e., Recall = 1 (or 100%). In other words, a highly sensitive model will flag almost everyone who has the disease and not generate many False Negatives.
For a good model, our precision and recall values should be high. we see that in the above model we have both precision ad recall as high
Most of the model predicts a probability, and when we predict, we usually choose this threshold to be 0.5. this threshold is not always ideal, and depending on this threshold, our value of precision and recall can change drastically, if for every threshold we choose, we calculate the precision and recall values, we can create a pot between these sets of values. this plot or curve is known as the precision-recall curve.
Before looking into the precision-recall curve, lets assume two lists.
y_true_1 = [0,1,1,0,0,1,0,0,1,1,1,0,0,0,0,1,0,0,0,1,0]
y_pred_1 = [0.25385164, 0.47153354, 0.52181292, 0.74550538, 0.05293734,
0.02329051, 0.78833001, 0.1690708 , 0.70097403, 0.51098548,
0.07442634, 0.55349556, 0.2294754 , 0.37426226, 0.16770641,
0.27747923, 0.82226646, 0.62389247, 0.41162855, 0.01400135,
0.46683325]So, y_true is our targets, and y_pred is the probability values for a sample being assigned a value of 1. so, now we look at probabilities in prediction instead of the predicted value (which is most of the time calculated with a threshold at 0.5)
precisions = []
recalls = []
# how we calculated threshold will be explained further
thresholds = [0.49344837, 0.6820013 , 0.13756598, 0.4702898 , 0.87279533,
0.6297947 , 0.33575179, 0.50324857, 0.1237034 , 0.43555069,
0.66494372, 0.60502148, 0.55022514, 0.57837422]
# for every threshold, calculate predictions in binary
# and uppend calculated prcision ad recalls
# to their respective lists
for i in thresholds:
temp_prediction = [1 if x >= i else 0 for x in y_pred_1]
p = precision(y_true_1, temp_prediction)
r = recall(y_true_1, temp_prediction)
precisions.append(p)
recalls.append(r)
Now, we can plot these values of precisions and recalls
import matplotlib.pyplot as pltplt.figure(figsize=(7,7))
plt.plot(sorted(recalls), sorted(precisions))
plt.xlabel('Recalls', fontsize=15)
plt.ylabel('Precisions', fontsize=15)
plt.show();
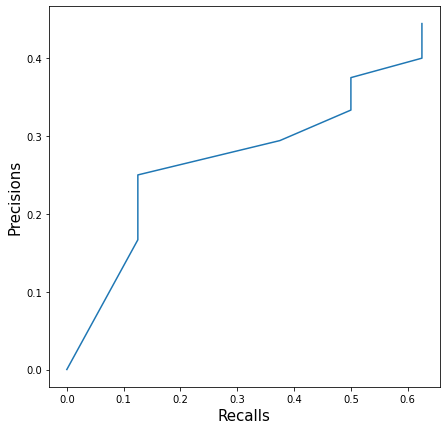
This precision-recall curve looks very different from what you might have seen on the internet. It’s because we have taken few instance points.
You will notice that its challenging to choose a value of threshold that gives both good precision and recall and values. if the threshold is too high, you have a smaller number of true positive and a high number of false negatives. This decreases your recall; however, your precision score will be high. If you reduce the threshold too low, false positive will increase a lot, and precision will be less.
Both precision and recall range from 0 to 1 and a value closer to 1 is better.
F1-Score:
F1-score is a metric that combines both precision and recall. It is defined as a simple weighted average (harmonic mean) of precision and recall.
F1-Score = 2*precision x recall/(precision + recall)
We can also find f1-score based on tp/fp and fn using below equation
F1-Score = 2TP/(2TP+FP+FN)
def f1(y_true, y_pred):
'''
Function to calculate f1 score
:param y_true: list of true values.
:param y_pred: list of predicted values.
:return: f1 score
'''
p = precision(y_true, y_pred)
r = recall(y_true, y_pred)
f1 = 2*p*r/(p+r)
return f1from sklearn.metrics import f1_score
f1(y_test, y_pred), f1_score(y_test, y_pred)(0.9543568464730291, 0.9543568464730291)
From above we can observe that both our custom f1-score and sklearn f1-score values are same.
Instead of looking at precision and recall individually, you can also just look at f1-score.
- Same as for precision, recall and accuracy, F1-score also ranges from 0 to 1. The perfect prediction model has F1 score of 1. When dealing with datasets that have skewed targets, we should look at F1 (or precision and recall) instead of accuracy.
Other crucial terms
TPR or True positive rate, which is the same as recall.
TPR = TP/(TP + FN)
TPR or Recall is also know as sensitivity.
def tpr(y_true, y_pred):
'''
Function that return TPR
:param y_true: list of true values.
:param y_pred: list of predicited values.
:return tpr value
'''
tp = true_positive(y_true, y_pred)
fn = false_negative(y_true, y_pred)
try:
tpr = tp/(tp+fn)
except:
tpr = 0
return tprFPR or False positive rate, which is defined as
FPR = FP/(TN + FP)
def fpr(y_true, y_pred):
'''
Function to return fpr
:param y_true: list of true values.
:param y_pred: list of predictied values.
:return: fpr value
'''
fp = false_positive(y_true, y_pred)
tn = true_negative(y_true, y_pred)
try:
fpr = fp/(tn+fp)
except:
fpr = 0
return fpr1- FPR is known as specifity or ture negative rate or TNR
There are a lot of terms, but the most important ones out of these are only TPR and FPR.
Area under the curve or (area under the ROC(receiver operating characteristic curve) AUC
Let’s assume that we have only 15 samples and their target values are binary:
Actual targets : [0, 0,0,0,1,0,1,0,0,1,0,1,0,0,1,0,1]
we train a model like the random forest, and we can get the probability of when a sample is positive.
Predicted probabilities for 1: [0.1, 0.3, 0.2, 0.6, 0.8, 0.05, 0.9, 0.5, 0.3, 0.66, 0.3, 0.2, 0.85, 0.15, 0.99]
For a typical threshold of >=0.5, we can evaluate all the above values of precision, recall/TPR, F1 and FPR. But we can do the same if we choose the value of the threshold to be 0.4 or 0.6. In fact, we can choose any value between 0 and 1 and calculate all the metrics described above.
Lets calculate only two values, through: TPR and FPR.
tpr_list = []
fpr_list = []
# actual target
y_true = [0, 0,0,0,1,0,1,0,0,1,0,1,0,0,1]
# predicted probabilities of a sample being 1
y_pred = [0.1, 0.3, 0.2, 0.6, 0.8, 0.05, 0.9, 0.5, 0.3, 0.66, 0.3, 0.2, 0.85, 0.15, 0.99]
# Hand made threshold
threshold = [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.85, 0.9, 0.99, 1.0 ]
# loop over all threshold
for thresh in threshold:
# calculate predictions for a given threshold
temp_pred = [1 if x >= thresh else 0 for x in y_pred]
# calculate trp
temp_tpr = tpr(y_true, list(temp_pred))
# calculate fpr
temp_fpr = fpr(y_true, list(temp_pred))
# append tpr and fpr to listss
tpr_list.append(temp_tpr)
fpr_list.append(temp_fpr)df = pd.DataFrame({'Threshold':threshold, 'tpr':tpr_list, 'fpr':fpr_list})
df
Threshold tpr fpr 0 0.00 1.0 1.0 1 0.10 1.0 0.9 2 0.20 1.0 0.7 3 0.30 0.8 0.6 4 0.40 0.8 0.3 5 0.50 0.8 0.3 6 0.60 0.8 0.2 7 0.70 0.6 0.1 8 0.80 0.6 0.1 9 0.85 0.4 0.1 10 0.90 0.4 0.0 11 0.99 0.2 0.0 12 1.00 0.0 0.0
If we plot the above table as TPR on the y-axis and FPR on the X-axis, we will get a curve as shown below
plt.figure(figsize=(7,7))
plt.fill_between(fpr_list, tpr_list, alpha=0.4)
plt.plot(fpr_list, tpr_list, lw=3)
plt.xlim(0, 1.0)
plt.ylim(0, 1.0)
plt.xlabel('FPR', fontsize=15)
plt.ylabel('TPR', fontsize=15)
plt.show()
This curve is also known as the Receiver operating characteristic (ROC). And if we calculate the area under the ROC curve. we are calculating another metric which is used very often when you have a dataset which has skewed binary targets.
This metrics is known as the Area under ROC curve or Area under the curve or just simply AUC. there are many ways to calculate the area under the roc curve.
from sklearn.metrics import roc_auc_score
roc_auc_score(y_true, y_pred)0.8300000000000001
AUC values range from 0 to 1
- AUC = 1 implies you have a perfect model. Most of the time, it means that you made some mistake with validation and should revisited data processing and validation pipeline of yours. if you didn't make any mistakes, then congratulations, you have the best model one can have for teh dataset you built it on.
- AUC = 0 implies your model is very bad( or its very good!) try inverting the labels .
- AUC = 0.5 implies that your predictions are random. so for any binary classification problem, if I predict all target as 0.5, I will get an AUC of 0.5
After calculating probabilities and AUC, you would want to make predictions on the test set. Depending on the problem and use-case, you might want to either have probailites or actual classes. if you want to have probabilities, its effortless. You already have them. If you want to have classes, you need to select a threshold. In the case of binary classification, you can do something like the following.
Prediction = probability >= threshold
Which means, that prediction is a new list which contains only binary variables. An item in prediciton is 1 if the probability is greater than or equal to a given threshold else the value is 0.
We can use ROC curve to choose this threshold!. The ROC curve will tell you how the threshold impacts false positive rate and true positive rate and thus, false positive and true positives. you should choose the threshold that is best suited for your problem and datasets.
Log Loss:
In case of a binary classification problem. we define log loss as:
Log Loss = -1.0 x (target x log(prediction) + (1-target) x log(1-prediction) )
where target is either 0 or 1 and prediction is a probability of a sample belonging to class 1.
For multiple samples in the dataset, the log-loss over all samples is a mere average of all individual log losses. ONe thing to remember is that log loss penalizes quite high for an incorrect or a far-off prediciton
i.e log loss punishes you for being very sure and very wrong.
log_loss(y_true, y_proba)0.49882711861432294from sklearn.metrics import log_loss
log_loss(y_true, y_proba)0.49882711861432294
Thus, our implementation is correct. Implementation of log loss is easy interpretation may seem a bit difficult. You might remember that log loss penalizes a lot more than other metrics
Multi-Class classification:
There are three different ways to calculate this which might get confusing from time to time. Lets assume we are interested in precision first. we know that precision depends on true positives and false positives.
- Macro averaged precision:
Calculate precision for all individually and then average them.
- Micro averaged precision:
Calculate class wise true positive and false positive and then use that to calculate overall precision.
- Weighted precision:
Same as macro but in this case, it is weighted average depending on the number of items in each class.
Lets compare our implementation with the sklean to know if we implemented it right
from sklearn import metricsy_true = [0,1,2,0,1,2,0,2,2]
y_pred = [0,2,1,0,2,1,0,0,2]macro_precision(y_true, y_pred), metrics.precision_score(y_true, y_pred, average='macro')(0.3611111111111111, 0.3611111111111111)micro_precision(y_true, y_pred), metrics.precision_score(y_true, y_pred, average='micro')(0.4444444444444444, 0.4444444444444444)weighted_prediction(y_true, y_pred), metrics.precision_score(y_true, y_pred, average='weighted')(0.39814814814814814, 0.39814814814814814)
Similarly, we can implemented the recall, f1-score, AUC and log-loss for multi class.
Confusion matrix:
A Confusion matrix is an N x N matrix used for evaluating the performance of a classification model, where N is the number of target classes. The matrix compares the actual target values with those predicted by the machine learning model.
Confusion matrices are widely used because they give a better idea of a model’s performance than classification accuracy does. For more information please check below reference link
Reference links:
- https://medium.com/analytics-vidhya/what-is-a-confusion-matrix-d1c0f8feda5
- https://medium.com/@fardinahsan146/accuracy-is-not-accurate-6eb321f2999c
- https://medium.datadriveninvestor.com/9-types-of-performance-evaluation-for-classification-machine-learning-modeling-c6e73e97e528
- https://scikit-learn.org/stable/modules/classes.html#module-sklearn.metrics
- https://www.amazon.in/Approaching-Almost-Machine-Learning-Problem-ebook/dp/B089P13QHT